Haxe Autumn Report - Simon Krajewski
Начинаю выкладывать переводы докладов с прошедшей 13 октября HaxeUp Sessions 2018. Записи всех докладов можно посмотреть на youtube.

К сожалению на конференции Роберт Конрад не смог выступить (подвел транспорт), но он обещал сделать публикацию в своем блоге по теме несостоявшегося доклада.

Первым выступил Саймон Кражевски, в своем докладе он рассказал об изменениях в компиляторе, над которыми команда работала в течение этого года.


С момента выпуска Haxe 4.0.0preview3 в репозиторий было внесено около 900 коммитов.
Число открытых issues снизилось с ~900 до ~600.
В команде появился новый участник - Джордж Корни, который занимается генератором экстернов для html (ранее это направление было заброшено).
Бен Моррис помог в доработке клиента для командной строки.
Также продолжают свою работу:
- Энди Ли продолжает поддерживать CI-интструменты;
- Йенс Фишер в основном занимается поддержкой Haxe в Visual Studio Code, но также участвует во множестве других Haxe-проектов;
- Кауи Ванек продолжает поддержку системы ночных сборок компилятора;
- Джастин Дональдсон работает над поддержкой Lua в Haxe;
- Александр Кузьменко занимается поддержкой PHP;
- Nicolas Cannasse продолжает работу над HashLink, а также генерирует множество интересных идей.

Одной из таких идей была реализация поддержки юникода в Haxe на всех поддерживаемых платформах:

Реализация поддержки юникода на всех платформах, в которые компилируется Haxe, оказалась довольно сложной задачей. Эта сложность обусловлена “природой” поддерживаемых платформ - разные платформы нативно поддерживают разные кодировки:
- ASCII: C/C++, Lua, PHP, старая версия интерпретатора макросов, neko
- UCS-2: JavaScript, FLash
- UTF-16: Java, C#
- UTF-32: Python
Из-за этого решение данной задачи заняло несколько лет.
Теперь на всех платформах поддерживается как минимум кодировка UCS-2. Для этого пришлось “подтянуть” работу со строками на платформах, нативно поддерживающих ASCII-кодировку.

UTF-8 кодировка не была выбрана из-за медленного доступа к символам строки по случайному индексу. Эта низкая скорость обусловлена тем, что символы в строке могут занимать больше одного байта, поэтому, чтобы получить символ по индексу, необходимо пройти по всем символам строки от начала и до требуемого индекса.

В кодировке UCS-2 символы занимают по 2 байта, это значит, что доступ по случайному индексу быстр. Но с другой стороны очевидно, что строка в UCS-2 занимает больше места. Кроме того, 2 байта на символ означает, что могут поддерживаться только 65536 символов (Основная многоязычная плоскость). Все символы, находящиеся за пределами основной многоязычной плоскости (в том числе и эмодзи), представляются в виде “суррогатных пар” - такие символы представляются уже двумя числами. Например, если в Java/C#/JavaScript (то есть для строк в UTF-16 и UCS-2 кодировках) запросить длину строки, состоящей из одного эмодзи, то результатом будет “2”:

И теперь для представления строк в Haxe 4 используются следующие кодировки (поддержка строк в neko не была обновлена из-за того, что в будущем его использование планируется заменить на HashLink):

Но это означает, что, например, в C++ работа со строками стала “тяжелее” (т.к. строки на C++ ранее использовали кодировку ASCII, то есть по 1 байту на символ). То же касается и HashLink, и Eval (новый интерпретатор макросов в Haxe).
На примере Eval Саймон рассказал о работе по оптимизации работы со строками.
Сначала Саймон попытался использовать UCS-2 кодировку. При этом в зависимости от символов, входящих в строки, в Eval они делились на ASCII и не-ASCII строки.
Для ASCII-строк использовался прямой доступ по индексу (т.к. каждый символ занимает по 1 байту).
Для не-ASCII строк приходилось преобразовывать ASCII-символы в строке с помощью побитового сдвига.
Из-за такого разделения исходный код Eval для работы со строками представлял собой сплошные if’ы. Кроме того, для работы Окамловского макроса все равно было необходимо преобразовывать строки в UTF-8.

Также Саймон придерживался мнения, что при итерации по строкам пользователи не должны заботиться о суррогатных парах - итератор должен просто возвращать код символа в указанной позиции. Поэтому он решил, что для работы со строками в Eval будет использовать UTF-8.

Поначалу для этого использовалась реализация в лоб - для доступа к i-му символу необходимо пройти по всем предыдущим символам в строке. Однако данный подход оказался крайне медленным, например, dox намертво зависал при попытке сгенерировать документацию.

Таким образом, было необходимо отыскать способ оптимизации работы с UTF-8. И решение предложил Juraj Kirchheim, исходя из того, что в реальной жизни доступ к символам в строке практически никогда не является случайным, а осуществляется направленно. Поэтому в строке хранится дополнительная информация о текущем положении “курсора” в ней: текущий индекс символа и его смещение в байтах относительно начала строки. Такой подход позволяет значительно снизить число проходов по символам в строке. Например, если курсор находится на 5-м символе и требуется считать 10-й символ, то вместо прохода по 10 символам с начала строки мы сможем обойтись всего пятью. Такая выгода особенно существенна при работе с длинными строками.

Такая “быстрая” реализация UTF-8 в Eval оказалась быстрее первоначальной реализации UCS-2:

Для сравнения работы новой “быстрой” реализации UTF-8 и старой (без оптимизации с использованием курсоров) Саймон провел несколько тестов на строках длиной в миллион символов, результаты которых показаны на следующем слайде (больше = лучше):

Неудивительно что до оптимизации работы со строками dox не мог завершить работу.
Далее Саймон рассказал о других нововведениях в Haxe:

Новый итератор “ключ-значение”:
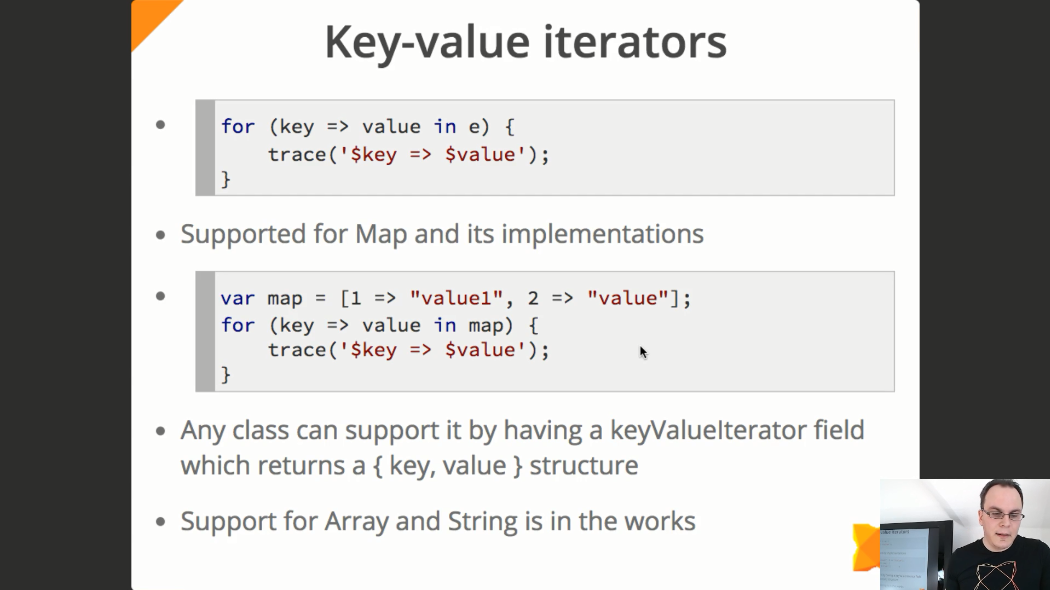
В настоящий момент такой итератор из коробки поддерживается только классом Map.
Поддержка для массивов и строк пока находится в работе, но будет завершена к финальному релизу Haxe 4.
Для того, чтобы реализовать поддержку нового итератора для пользовательских классов, достаточно чтобы у класса было поле keyValueIterator, возвращающее структуру вида {key, value}.
Новый синтаксис inline-вызовов, позволяет встраивать вызываемые функции даже если они не были объявлены как встраиваемые (inline):

Новая мета @:using, позволяющая добавлять статические расширения любым типам, даже перечислениям (enum):

XML-литералы. Теперь в код можно вставлять xml-документы, при этом корректность структуры xml (например, отсутствие закрывающей угловой скобки, или тэга) будет проверяться макросом на этапе компиляции.
Данная фича добавлена в основном для того, чтобы “скармливать” такие xml пользовательским макросам.

Теперь в качестве значений по-умолчанию можно задавать конструкторы перечислений. Однако, данная фича пока что работает только для конструкторов перечислений без аргументов:

Все перечисленные фичи доступны в Haxe 4.0.0.preview5, который уже доступен на официальном сайте.

Жаль только, что у Саймона не получилось выпустить эту версию в прямом эфире :)