Null safety. Александр Кузьменко
В своем докладе Александр Кузьменко рассказал о проблемах, связанных с нулевыми указателями, об имеющихся в Haxe способах их решения, а также о собственном плагине, предназначенном для решения проблемы Null-безопасности.
Видеоверсия доклада доступна на youtube.
Отдельно слайды презентации к докладу можно посмотреть здесь.

Что такое нулевой указатель, нулевая ссылка? Являются ли они значениями или нет, и если являются, то значениями какого типа? Или может быть они являются чем-то еще?

По словам Тони Хоара (автора понятия нулевого указателя) это было его ошибкой на миллиард долларов:
«Я не мог устоять перед искушением добавить в язык нулевой указатель (null), просто потому, что его так легко было реализовать. Это привело к бессчётному множеству ошибок, уязвимостей и сбоев, которые нанесли ущерб, наверное, в миллиард долларов за последние сорок лет.»
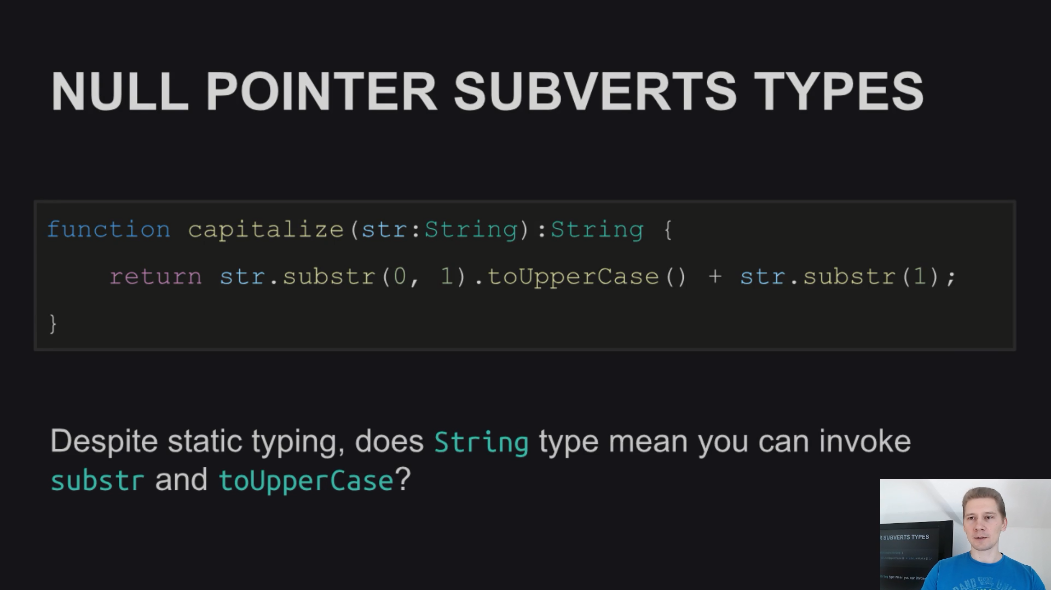
Безопасно ли вызывать методы substr() или toUpperCase() у строки в языках со статическими типами (Haxe в их числе)? Система типов обещает вам, что это допустимые операции, но фактически иногда это может приводить к падению программ из-за того, что строка, для которой вызываются эти методы, может быть нулевой, а у null нет ни полей ни методов.
Ошибка с нулевым указателем - наиболее распространенная из всех возможных. В качестве проверки этого утверждения достаточно поискать на гитхабе коммиты с заголовками вроде “Исправление нулевой ссылки” (fix null reference), “Исправление исключения, вызванного нулевым указателем” (fix npe), “Исправление нулевого указателя” (fix null pointer). Поиск по таким запросам даст более 11 млн. результатов. И если предположить, что каждое такое исправление ошибки заняло 2 минуты (что очевидно является очень оптимистичной оценкой), то получится что для их написания потребовалось более 40 лет непрерывной работы. И число таких ошибок и коммитов постоянно растет.
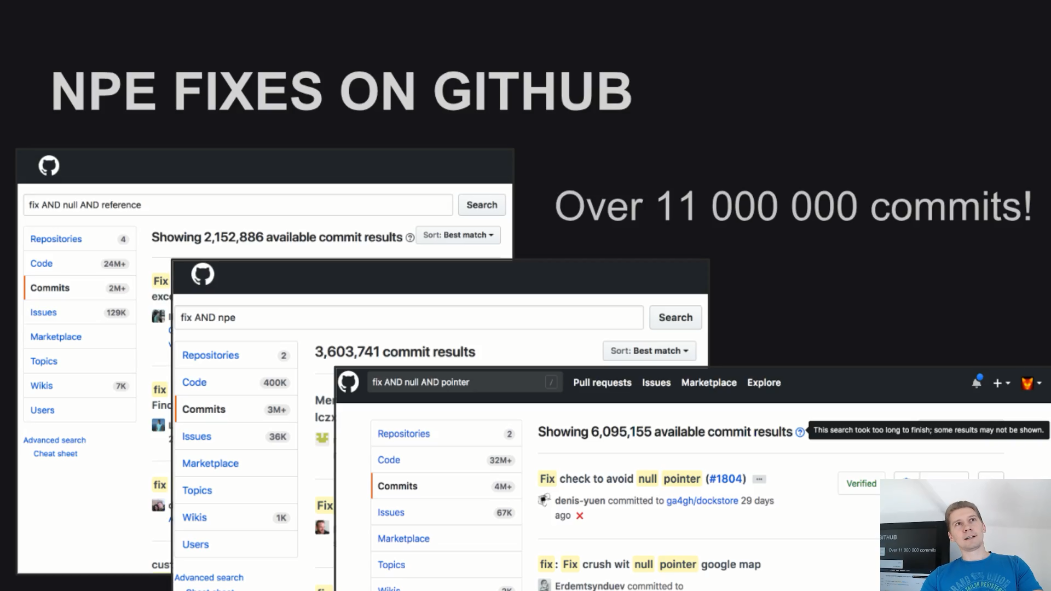
Эта оценка основана только на результатах поиска по публичным репозиториям на гитхабе, она не учитывает ошибки в приватных репозиториях, ошибки в коде, о которых мы никогда не узнаем. Поэтому можно смело говорить не о сорока годах, а о сотнях лет работы программистов.

Какие же средства предоставляет Haxe для того, чтобы обезопасить себя от такого рода ошибок? Вариантов немного:

Из коробки Haxe предоставляет нам специальный абстрактный тип Null<T>, который можно использовать в основном как средство документации кода - присутствие Null<T> в сигнатуре метода говорит о том, что он может принимать или возвращать нулевые значения. Единственное, что данный тип действительно делает - он “оборачивает” (boxing) значения базовых типов (Int, Float, String) на статических платформах.
Конечно, используя Null<T>, можно задокументировать весь код, а затем при вызове методов, в сигнатуре которых встречается Null<T>, всегда проверять значения на null. Но достаточно ли вы дисциплинированы, чтобы всегда так делать во всех случаях. Кроме того, всегда есть возможность забыть сделать такую проверку, или полениться дополнить документацию кода. А как насчет других членов команды, или автора используемой вами библиотеки?

Давайте посмотрим на следующий код:
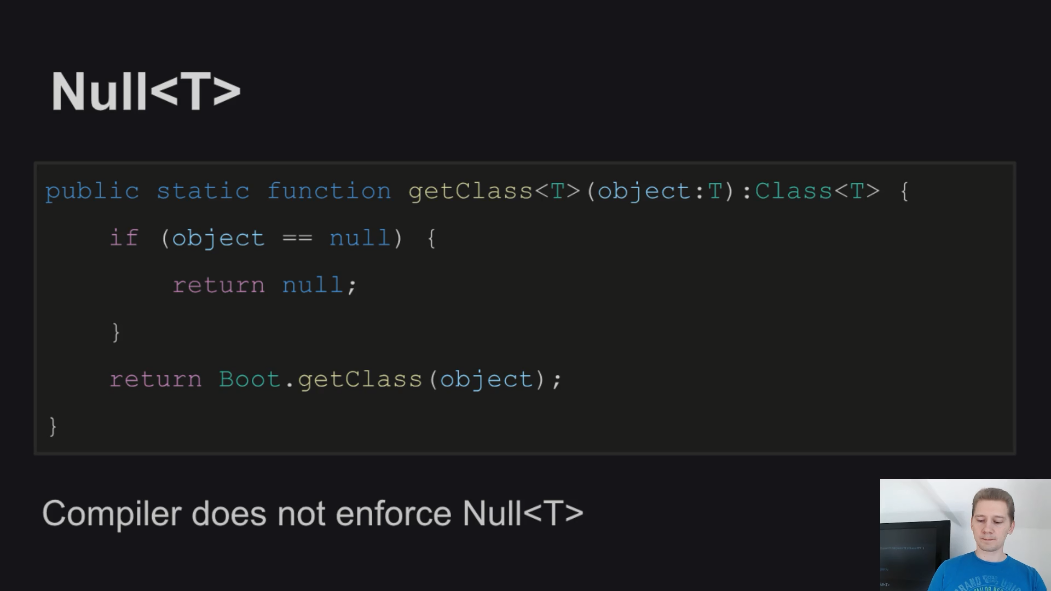
С первого взгляда может показаться, что это безопасный код, который не может послужить причиной отказа программы, т.к. метод проверяет значение аргумента перед тем как продолжить с ним работу. Но на самом деле этот код может вам жестоко отомстить в будущем - сигнатура метода говорит о том, что метод не ожидает от вас нулевого значения, а также обещает ненулевой результат. Однако если вы нарушите такое негласное соглашение, передав null в качестве аргумента, метод вернет null, что может послужить своего рода часовой бомбой, способной послужить причиной падения вашей программы в самый неожиданный момент.
Автор такого кода, скорее всего предполагал, что написал хороший отказоустойчивый код, т.к. добавил проверку на null, но забыл указать в качестве возвращаемого типа Null<Class<T></Class>> вместо Class<T>. И, кстати, это код из стандартной библиотеки Haxe.
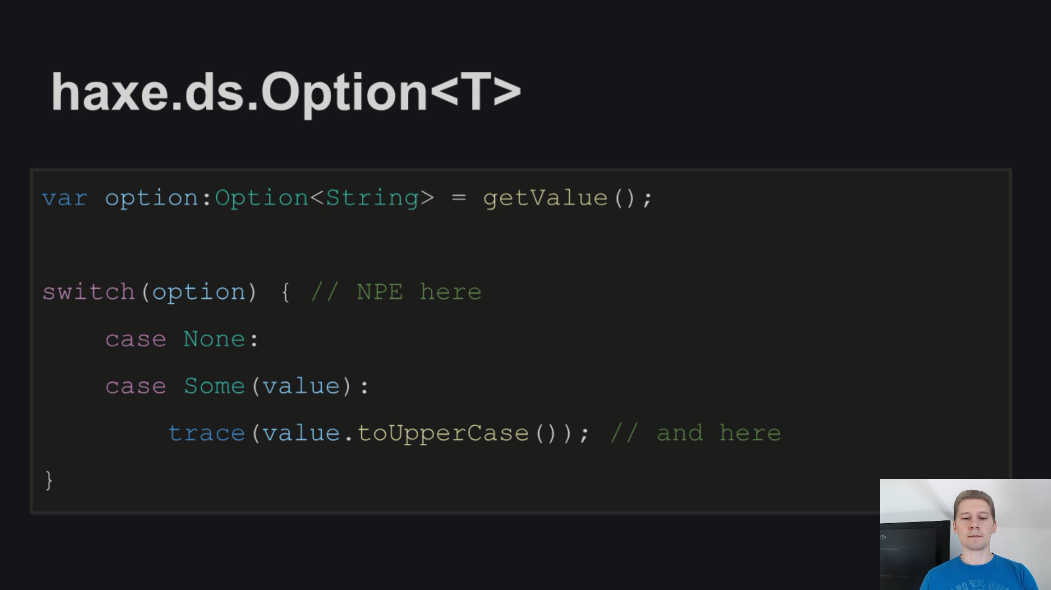
Другой вариант, предлагаемый в Haxe для повышения отказоустойчивости - использование типа haxe.ds.Option<T>. Компилятор не позволит использовать значение, которое хранится (обернуто) в переменной данного типа до тех пор, пока вы не проверите, что значение существует:

Но использование типа haxe.ds.Option<T> несет за собой дополнительные затраты ресурсов, т.к. он “оборачивает” значения любых типов (а не только базовых, как в случае с Null<T>).
Кроме того, переменная типа haxe.ds.Option<T> сама по себе может иметь значение null, также значение, обернутое в haxe.ds.Option<T>, также может быть null. Поэтому в следующем приведенном примере нулевое значение может встретиться в двух местах, то есть вероятность возникновения исключений, связанных с нулевым указателем, становится выше, чем если бы haxe.ds.Option<T> здесь не использовался:
Третий подход к решению подобных проблем был взят из сборника рецептов Haxe - использование абстрактного типа Maybe<T>, который всегда осуществляет проверку на нулевое значение перед тем, как что-то делать с ним:
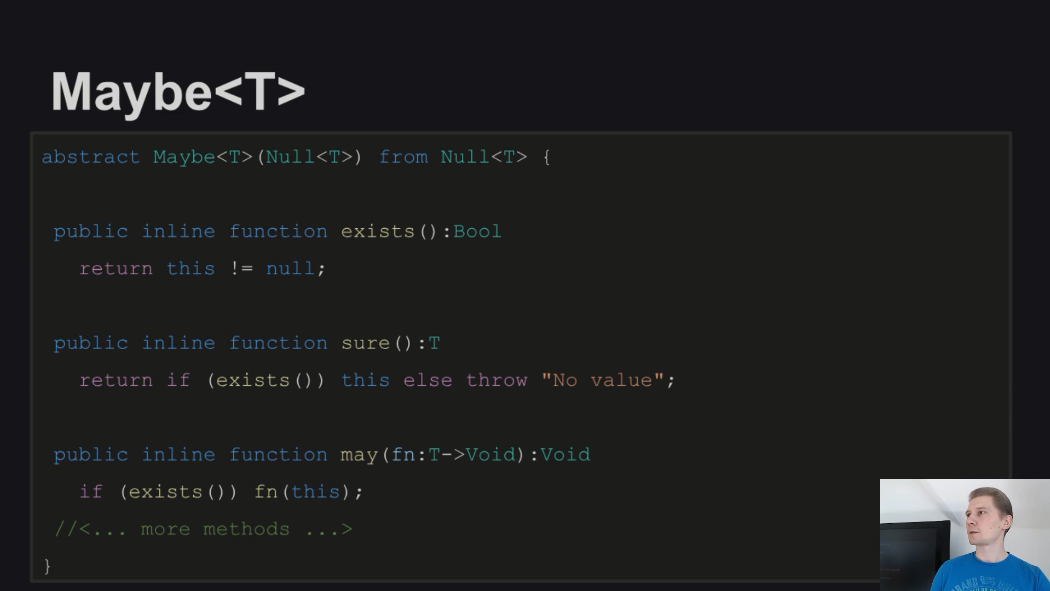
Но его недостатком является то, что при работе этого абстракта осуществляются излишние проверки на null: не только метод exists() делает это, но и все остальные методы данного абстракта. Поэтому генерируемый компилятором JavaScript-код при активном использовании Maybe<T> быстро становится нагромождением функций-замыканий.
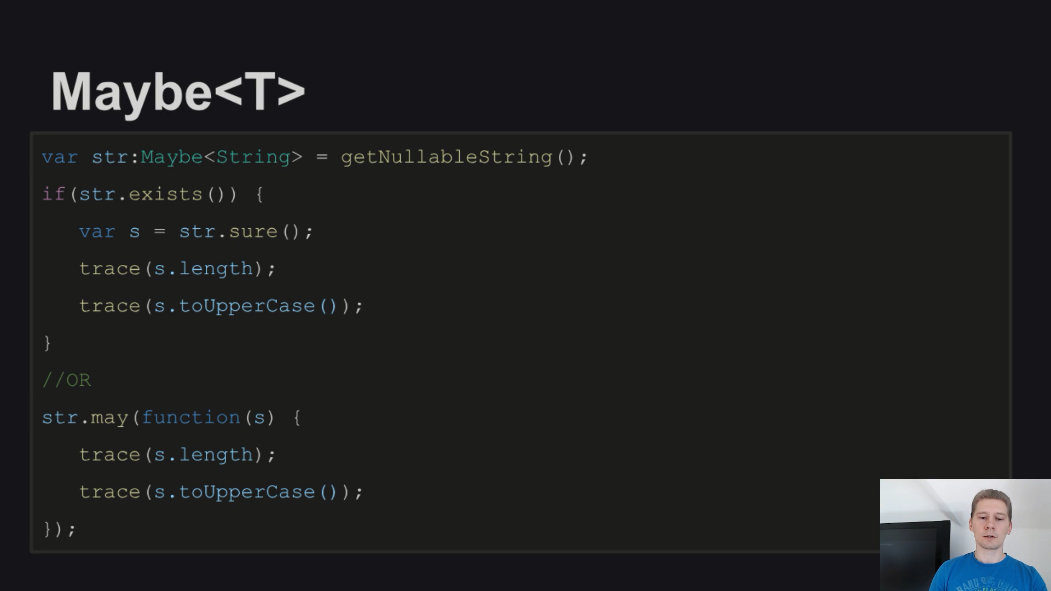
И самое важное, по мнению Александра, это то, что отсутствие Maybe в типе не гарантирует, что значение не может быть нулевым.
Что было бы, если компилятор Haxe поддерживал Null-безопасность?
В таком случае вместо использования перечисленных выше приемов компилятор попросту не позволил бы использовать нулевые значения там, где явно не указано, что такие значения допустимы, без обязательной дополнительной проверки значения на null.
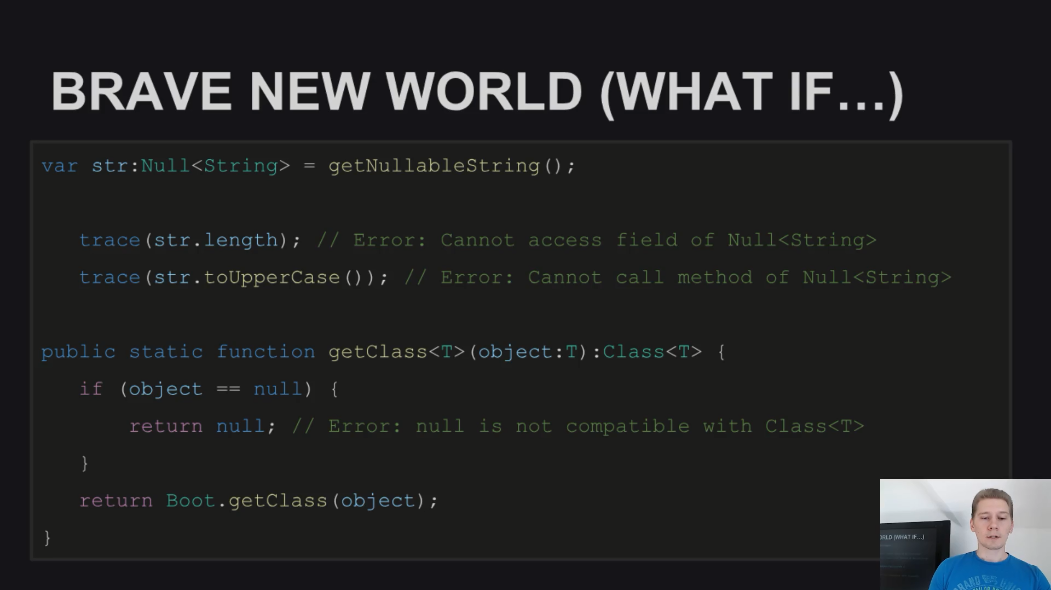
На следующем слайде показаны ошибки, которые возникали бы на этапе компиляции в случае поддержки Null-безопасности со стороны компилятора:
А на этом показан исправленный Null-безопасный код, который бы успешно компилировался:
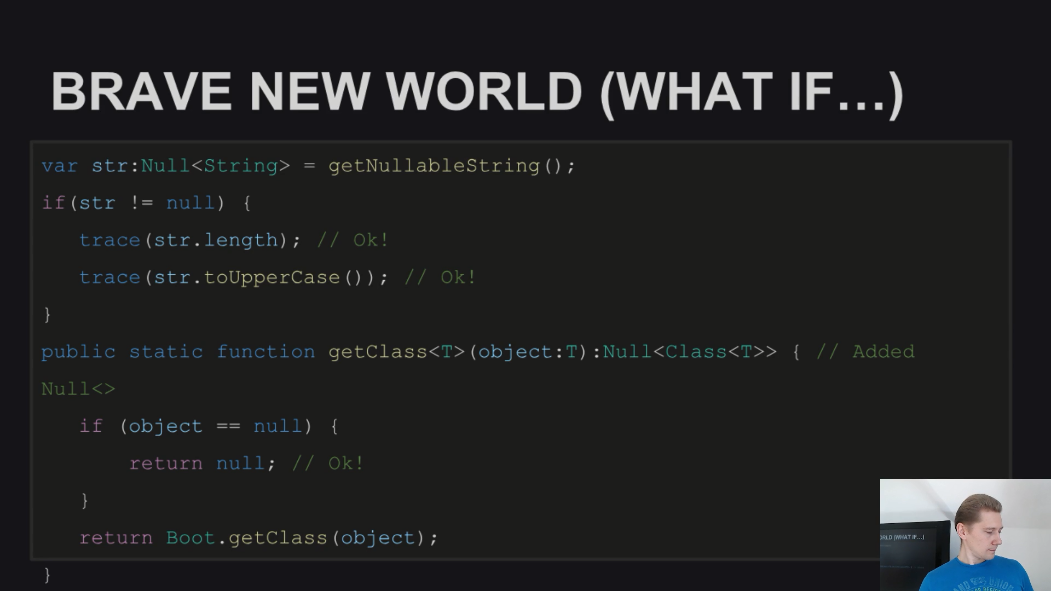
Здесь была добавлена проверка на null при работе со строкой, а также у метода getClass() явно указано, что он может возвращать нулевое значение.
Такой подход гораздо лучше использования абстракта Maybe<T>, т.к. если в описании типов переменных указать, что переменная не может принимать значение null, то компилятор не позволит присвоить переменной такое значение.
Но у него есть и недостатки:
-
проверки на
nullстановятся обязательными даже тогда, когда вы не беспокоитесь о Null-безопасности, например, пытаетесь набросать простой скрипт для выполнения какой-либо задачи; -
также проверки на
nullобязательны даже в случаях, когда вы уверены, что переменная не может иметь значенияnull, например, как в примере итерации по словарю, приведенном на следующем слайде:

Какие проблемы могут помешать или затруднить внедрение Null-безопасности в Haxe?

Во-первых, это спецификация массива - чтение в массиве за его пределами всегда возвращает null, но в сигнатуре это явно не указано, поэтому чтение за пределами массива не может быть отловлено:
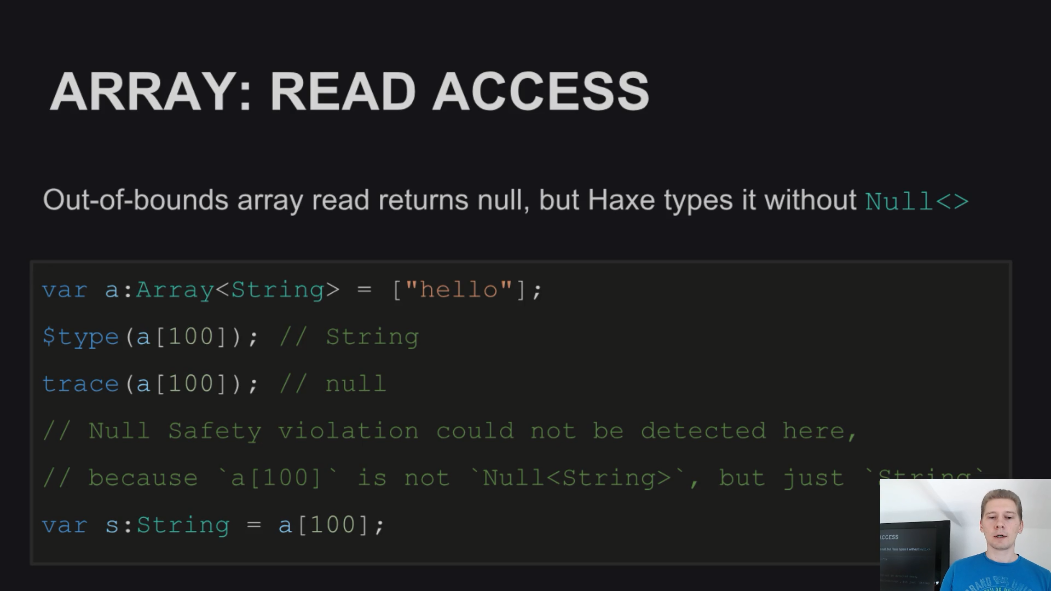
То же касается и записи в массив - при записи за пределами массива, весь промежуток заполняется значением null. Сам же массив при этом типизирован, как Array<T>:
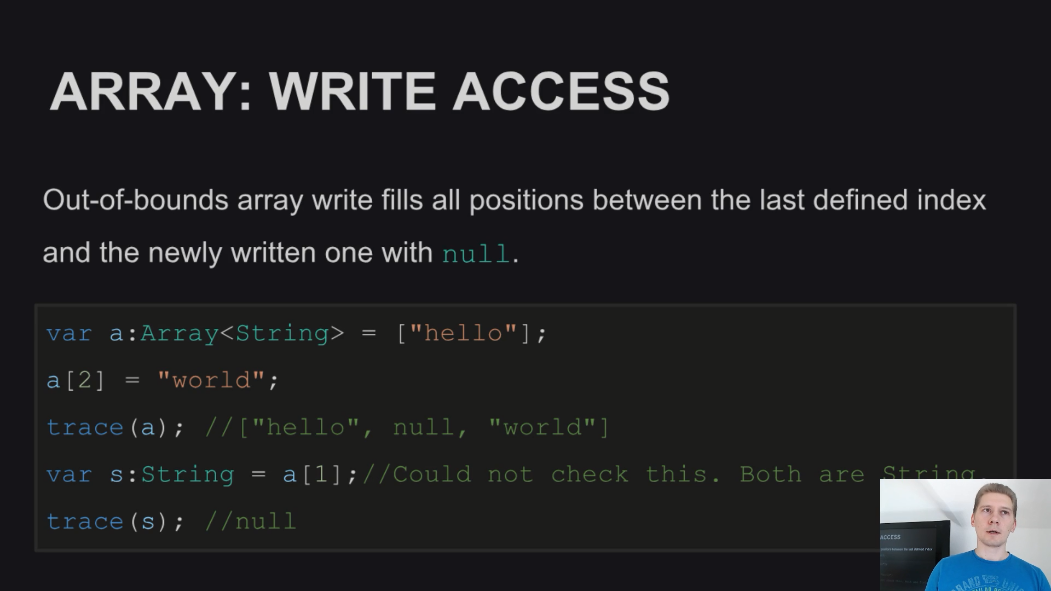
Еще одна проблема связана с тем, что при работе с Map всегда возвращаются значения, которые могут быть null, даже в тех случаях, когда вы уверены, что этого быть не может. Из-за этого при работающей на уровне компилятора Null-безопасности становится необходимым всегда осуществлять проверку значений, получаемых из Map, что может быть излишним:

Эта проблема могла бы быть решена с помощью нового итератора “ключ-значение”, но для Map он реализован как сокращенная форма записи для старого итератора. Но что еще хуже с точки зрения Null-безопасности это то, что новый синтаксис обещает вернуть ненулевое значение, при этом во время итерации допускается удалять записи из Map, таким образом итератор все же cможет вернуть нулевое значение, а компилятор не сможет отловить такую ситуацию:

Еще одна проблема - это унаследованный код, написанный без соблюдения принципов Null-безопасности. Такой код попросту может и не скомпилироваться. Например, попытка скомпилировать стандартную библиотеку Haxe в режиме Null-безопасности выдаст более 800 ошибок.
Поэтому решением такой проблемы является реализация возможности включать такой режим компиляции только для нового кода, для заданных пользователем пакетов.

Но что делать со сторонним кодом, который умышленно возвращает null, но при этом не указывает Null<T> в типах? Это могут быть экстерны или библиотеки из haxelib, написанные без соблюдения Null-безопасности. Тут есть два пути, оба со своими минусами:
- первый - считать весь “внешний” код небезопасным. Это приведёт к большому количеству кода с проверками там, где они на самом деле не нужны;
- второй - исправлять типизацию, создавать Issue и пул-реквесты. Это истинный путь опенсорса. И автор призывает поступать именно так.

Следующий пункт на самом деле не является проблемой, но является пожеланием - добавление оператора безопасной навигации. Данный бинарный оператор работает следующим образом: если первый аргумент (левая часть выражения) является null, то он возвращает null, в противном случае он возвращает значение второго аргумента (правая часть выражения). Таким образом, оператор безопасной навигации позволяет сократить написание требуемых проверок на null.
К сожалению в Haxe использовать постфиксный ? нельзя, т.к. это породит неоднозначность интерпретации (т.к. в тернарном операторе ? уже используется). Однако в таких языках как C# и Perl эти операторы совместно существуют, поэтому Александр надеется, что и в Haxe это будет реализовано.

Оказывается, что в компиляторе Haxe уже более года существует поддержка плагинов. И Александр воспользовался этой возможность написал плагин для реализации Null-безопасности (и некоторых других фич). Далее речь пойдет о возможностях этого плагина.

Главная фича - это, конечно, поддержка Null-безопасности, которую можно включать на уровне заданных пользователем пакетов. При этом вы не сможете присвоить значение переменным с типами, отличными от Null<T>, до тех пор, пока не добавите проверку присваиваемого значения на null. Таким образом, будет невозможно получить Null Pointer Exception, т.к. случайно присвоить нулевое значение уже не получится.
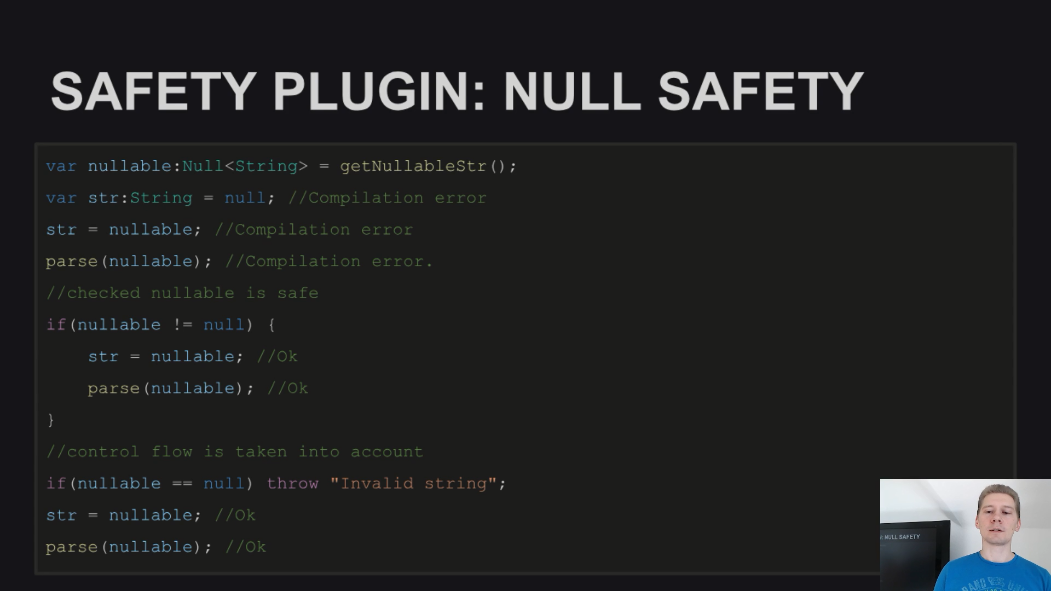
Плагин также осуществляет проверку значений полей у класса, они либо должны иметь значения по-умолчанию, либо быть проинициализированы в конструкторе. Значение поля будет невозможно использовать до тех пор, пока оно не будет инициализировано.
Это также убережёт вас от проблем с математикой на платформах, где для числовых типов по умолчанию используются значения null или NaN.

В плагине также есть возможность исключить определенный код из проверок на Null-безопасность (например, если вы уверены в безопасности написанного кода, который критичен для производительности работы приложения). Для этого используется мета @:safety(unsafe), которую можно указывать как отдельным полям, так и классам:

Также в плагине есть специальный typedef Unsafe<T>, для которого проверки Null-безопасности отключены. Плюс данный typedef позволяет отключать такие проверки для отдельных выражений:

Оператор безопасной навигации: т.к. использовать для него постфиксный ? нельзя, а постфиксный ! можно, то Александр выбрал его для этой роли. При использовании данного оператора автодополнение кода будет продолжать работать.

Еще одна фича - это SafeArray, которая призвана решить названные ранее проблемы Null-безопасности у массивов в Haxe, запрещая чтение/запись в массиве за его границами (иначе будет брошено исключение OutOfBoundsException).
С помощью дополнительного аргумента --macro Safety.safeArray(my.pack) при вызове компилятора все определения массивов в заданном пакете будут преобразованы в SafeArray.

Safe API может быть полезна разработчикам библиотек, т.к. она добавляет автоматические проверки на null у аргументов публичных методов, доступных пользователям вашей библиотеки. И если в метод, для которого включено Safe API, попробовать передать null, то будет брошено исключение IllegalArgumentException.

Также в плагине есть несколько статических расширений для удобства работы программиста, например, для случаев, когда нужно один раз считать значение переменной и не хочется при этом писать дополнительных проверок на null:
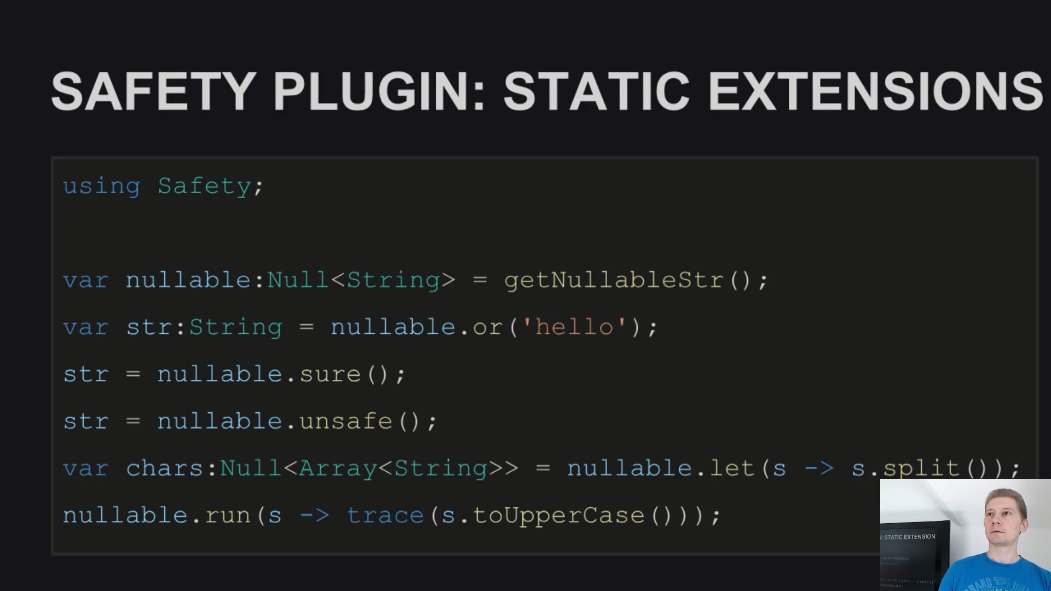

И в качестве краткого вывода можно сказать, что, несмотря на все упомянутые проблемы, Null-безопасность в Haxe возможна.